
RAGの精度が上がらない?設定を見直してみよう!

おはこんばんちは。野球好きのりまきです。
仕事でRAGを使って何かしらを作る機会があったので、DifyのRAG(ナレッジ)が使いやすいと聞いたので触ってみました。
なんでRAG使うねん?やけど、RAGを使うメリットって、ハルシネーションのリスク軽減。
間違いが多発するのを減らしたいのと、必要な情報の中から考えて欲しいから使うことにしました。
Difyのナレッジベースの公式の説明はコチラ
ナレッジをインポート、、、その先に
Difyのナレッジは、以下の3つから選択できます。
- テキストファイルからインポート
- Notionから同期
- ウェブサイトから同期
今回は「テキストファイルからインポート」を選択して、Excelファイルをアップロードしました。
チャンク設定
ファイルをアップロードするだけで使えると思ってましたが、色々と設定するものがあります。
まずはチャンク設定
チャンクとは?
テキストを意味のある小さな単位(チャンク)に分割したものです。
このチャンクごとにベクトル化(文章や単語などのテキストデータを、AIが理解・計算できる数値の集まり)が行われます。
チャンクは検索単位になるので、チャンクのサイズをプレビュー機能を使って確認します。
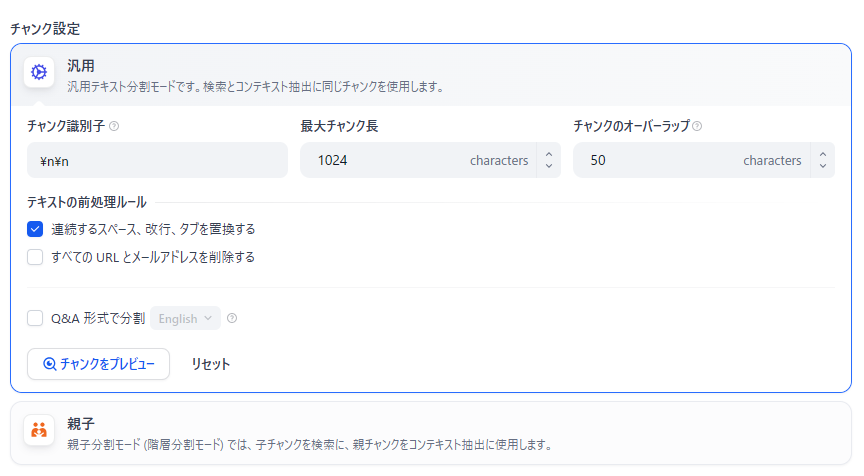
チャンクの設定
Difyのチャンクは以下の設定があります。
| 項目名 | 内容 |
|---|---|
| チャンク識別子 | 文章をどこで区切るかを決める設定です。「\\n\\n」(2回の改行)で段落ごとに分けます。 |
| 最大チャンク長 | 1つのかたまり(チャンク)の最大の長さを決めます。例:500トークン。長すぎる文章を防ぎます。 |
| チャンクのオーバーラップ | 前のチャンクの最後の一部(例:50トークン)を、次のチャンクの先頭に重ねて入れ、話の流れを保ちます。 |
| テキストの前処理ルール | スペース・改行・タブを整理し、URLやメールアドレスなどの不要な情報を削除して、文章をきれいにします。 |
「最大チャンク長」と「チャンクのオーバーラップ」はRAGの精度に影響を与えるので、テキストデータ量に合わせて設定するのがおすすめです。
最大チャンク長
今回、私は野球選手のDBをインポートしています。
背番号、名前、生年月日、身長、体重、投打の情報です。すべてが短い単語になってるので、チャンクは短めがいいですよね!
| 用途 | 推奨チャンクサイズ | 理由 |
|---|---|---|
| FAQや明確なQ&A | 小さめ(200〜500文字) | ピンポイントで検索しやすくなる |
| 論文やマニュアル | 中くらい(500〜1000文字) | 文脈を含んだ情報を保持 |
| ストーリーや会話ログ | 大きめ(1000〜1500文字) | 長い文脈の把握が必要なため |
分からなかったら、ついデフォルトのままで使ってしまいたくなりますが、今回のように短いチャンク長でいいのに、最大長を大きく設定すると以下のデメリットもありますので、チャンク設定は気を付けましょう!
逆に長い文章に対して短いチャンクにしてしまうと、文章が途中で途切れたりしてしまいます。
| デメリット | 詳細 |
|---|---|
| 意味のない結合が起きる | 本来独立していた短い文や段落が、無理やり1つのチャンクにまとめられ、文脈が不自然になる可能性があります。 |
| ノイズが増える | 関連性の薄い複数の内容が1チャンクに含まれると、RAGで「質問に関係ない情報」まで検索結果に出てくることがあります。 |
| 検索精度の低下 | 長いチャンクだと、質問とマッチする部分があっても、その周辺に余計な文脈が混じってスコアが分散し、必要な情報が選ばれにくくなります。 |
| ベクトルの意味がぼやける | 短い情報(例:「項目見出し+1文」など)を無理に束ねると、埋め込み(ベクトル化)したときに「何を表しているのか分からない平均的なベクトル」になりやすい。 |
| 更新や再インデックス時のコスト増 | 1チャンクあたりの情報量が増えるため、再ベクトル化の際のコスト(計算・API料金)が無駄に高くなります。 |
| リアルタイム性の低下 | チャンクサイズが大きいと、リアルタイム検索時の応答速度が落ちることがあります(処理データ量が増えるため)。 |
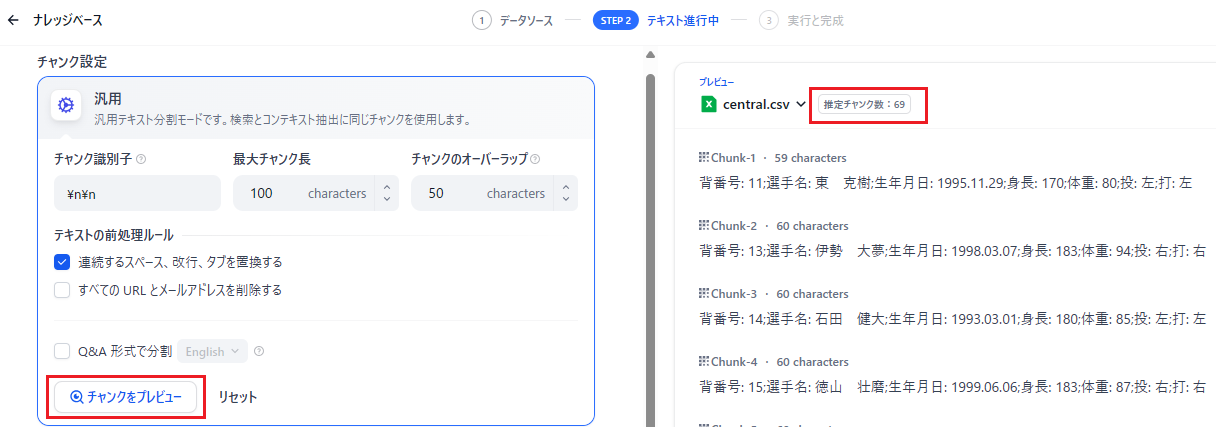
チャンクを100にしてプレビューしてみます。
左スペースにチャンクで分けられたテキストが確認できます。「推定チャンク数」も提案してくれます。
QA方式で分割
チャンク設定にある「Q&A形式で分割」設定があります。
この設定はアップロードされたドキュメントを「質問(Q)」と「その答え(A)」のペアごとに分けて、ナレッジ(知識ベース)に登録をします。
QA方式は「質問応答」に適しています。例えば、製品マニュアルや社内規定等に基づくチャットや検索アシスタント等は特に適しています。
QA方式のメリットは、Q&Aの形式に合った資料をアップロードする場合は、回答の精度や一致度が高くなること、チャンクよりも「質問との関連性」がはっきりしていて、RAGでのマッチングがしやすくなります。
ただし!!!追加のトークンが必要になるので従量課金制ではコストが上がりやすいことに気を付けてください。
インデックス方法
インデックスは、チャンク分割したナレッジから適切なチャンクを見つけるために必要です。「高品質」と「経済的」のどちらかを選択します。
「高品質」→「経済的」にダウングレードはできません。「経済的」から「高品質」へ変更することはできるので、一旦「経済的」で様子をみてもいいかもしれません!
ただし、「高品質」の方が制度は高く、「経済的」はチャンク内の単語と検索時の単語が異なる場合検索にヒットしにくい、しないデメリットがあります。
参考までに、違いをまとめてみました。
| 項目 | 高品質(High Quality) | 経済的(Economical) |
|---|---|---|
| 精度 | ◎ 高い | △ やや劣る |
| チャンクサイズ | 小さい(細かく分割) | 大きい(まとめて分割) |
| オーバーラップ | あり(文脈重視) | 少ない or なし |
| インデックス数 | 多くなる(処理重め) | 少なくなる(軽い) |
| ストレージコスト | 高め | 低め |
| 処理スピード | 遅め(詳細処理) | 速め(効率優先) |
| 向いている用途 | 正確な回答が必要なQAなど | ラフな検索や大量ドキュメント処理 |
検索設定
ユーザーの質問に対して、登録しておいた資料の中から「いちばん関係のある部分」を探す必要があります。
この「探し方(検索の方法)」を設定するのがこの画面です。
- ベクトル検索(意味で探すAI検索) AIが「質問の意味」と「文章の意味の近さ」を比べて、関係ありそうな情報を探す方法です。
- 全文検索 単語がそのまま文章に入っているかどうかで探す方法です。PCでの「Ctrl+F(検索)」と同じイメージです。
- ハイブリッド検索 ベクトル検索 + 全文検索の合わせ技。意味と単語の両方で探して、AIが一番良いものを選んでくれます。
検索の詳細
- Top-K(トップK) 「意味が近い候補を何件まで出すか」を設定します。 数字を大きくするとたくさん見つけられますが、コストも増えてしまいます。 例:Top-K = 3 → 意味が近い上位3件だけ使って回答
- スコア閾値 「これくらい似ていたらOK」という合格ラインです。 0〜1の値。1に近いほど厳しく(精度アップ)、0に近いほどゆるく(拾いやすく)なります。
- Rerankモデル 候補の中から、AIがもう一度「一番良さそうな順」に並べてくれる機能です。 検索結果が分かりやすくなりますが、API接続が必要な場合もありますので、費用も少し増えてしまいます。品質重視の時はON、軽量運用ならOFFがおすすめです。
表にまとめてみましたので、参考にしてください。
| 項目 | 内容 | 説明 |
|---|---|---|
| ベクトル検索 | 意味で探すAI検索 | 表現が違っても意味が近ければヒットする |
| 全文検索 | 単語で探す | 単語が一致している文だけ見つける |
| ハイブリッド検索 | 両方使う | 精度が一番高い検索方法 |
| Top-K | 候補数の上限 | 何件までAIに渡すか(例:3件) |
| スコア閾値 | 似てる度の合格点 | 0.5〜0.7が標準的。高くすると厳しくなる |
| Rerankモデル | 順位の並べ替え | AIが一番良さそうな答えを前に出してくれる |
いかがでしたでしょうか。
Difyのナレッジが少しでも扱いやすくなるといいなと思います。
自分のデータで早速試してみましたが、なんと!!
Excelはシート毎にで分けているデータは認識されないようで、複数シートで作成していたデータは最初のシートしか使えない!ということが分かり、きれいにオチがついたなぁと思いますが、データを整理してチャレンジしてみます!
他の記事もいかがでしょうか?